About SCM Source Code Managment System
Sun 27 September 2015 by Naveen TamanamGIT The Source Code Management System(SCM)
Many people uses version control system but they have on idea why they are using it, as the team is using, they will also use it get work done.
Why do we need version control system? Here are the few requirements, from where the SCM idea comes.
See the project directory with out version control system.
When ever you think to have snap shot of your source code for that particular moment, then you have to copy your source code directory by naming it according to that moment. Like wise you may do it with tarballs to save memory. Its horrible....not?, you will end up with endless tarballs or directories as per the project.
Just think, your other developer asked about release code that you did on some x day. Then you have to send him whole project directory if every file got changed and he is not having those changes. You did some performance fixes, it takes 70% refactoring, and it's an experiment then you should keep your project directory backup, before you starting doing these performance fixes. And also you need to have directory/tarball when you completed with your changes, because you may not undo your 70% of changes if you want the last stable code that you have before 70% of refactoring for performance. If these changes are not stable and will take long time to get them stable, in such a case you will replace your production with the directory that you copied before you did performance fixes.
If we go like this, you will end up with whole hard disk with your single project. Even though, you will not dare to find some directory(If you think of directory as snap shot or save point).
Now come to team collaboration, there is no pretty much better way to communicate with the team with code changes up to dated as per time with out SCM. Some times your team will need to wait for the fixes those are being implemented by others, to get source code. In this case one person can work faster than the 10 persons. Because every body else will end up by doing nothing other than taking/giving changed files looking at differences, asking others about changes and finally preparing single file by combining working changes.
All this story about when we don't have source code management system. Now imagine the development with out SCM.
Thats why the version control system comes into picture.
Version control, also known as revision control, source control management, is the management of changes to files, programs and other information. Version control system allows us to track the incremental changes in files or content. Provides the ability for many developers to work on single file or project concurrently.
The project directory with SCM (GIT)
There are lot of SCM softwares out side including open source and commercial. Here are few....
- CVS
- SVN
- BitKeeper
- GIT
- Mercurial
There are lot of softwares available other than I have mentioned, you can find them at list of version control systems
We can classify the version control systems based on their model. That is centralized and distributed. You may call centralized as client server model. As there are many version control systems no one meet all requirements at all.
Here are few characteristics of version control systems, which will vary around each version control system.
- User interface
- Performance
- Memory management
- Learning cure
- Maintenance
Apart from them there are two other things to consider, Open source/Proprietary Centralized/Distributed
Lets have a look at GIT. GIT is a distributed revision control system which is especially designed for speed. It was designed by
Linus Torvalds in early 2005. It was designed to manage kernel source code, and for the BitKeeper
replacement. Linux kernel was managing with BitKeeper before GIT was invented. It's initial release was 7 April 2005. GIT is really helpful for open source projects where it supports merges much better than any other SCM.
Here is how GIT distributed(decentralized) model would look like.

this distributed model we will have history in every host, that here we can think of each machine as complete git repository. We can revert any other repository from any other repository in network in any hardware failuter. So git history is redundant here, cause it performance. You may call distributed version control system as DVCS. In DVCS there may be many central repositories.
And centralized model would look like:

In centralized model whole git history is resides in only central repository. We need to have connected via network to commit our changes unlike git(distributed). It required additional maintenance and need to take source code backups to regret central repository from any hardware failure of so.
First time with GIT:
Every git repository is nothing but a directory either on server or locally in your machine.
Creating the GIT repository is very simple, go to the directory that you would like make it as your git repository. To make sure you are in that directory justify it by the command pwd.

Here I would like to make my PROJECT directory as GIT repository. It's simple, with the following command.

One more thing, if your directory is git repository you would have .git inside.

GIT use to track changes and all with this directory.
We do save our changes with in commit. You may think each commit as one save point. You can go back to that history or save point when ever you want. You can tag commits with your version numbers. That is like v1.0, v2.0, v3.2,.... so on. You may call commit as revision or version as well.
As GIT uses a unique SHA1 to identify the commit. So each revision can be described by 40 characters hexadecimal string. Instead of mentioning this long commit hash into the releases and executables git users tag that specific commit with version number. So we can identify and get that specific source from the incremental git source tree for that version.
For each commit we will give some descriptive message we will call that as commit message. Here is the commit look like, it's from git source.

Here we see four things, commit, author, date and commit message. In each commit git stores the author name and his email. So we need to configure git to take our name and email and other settings if required to have them in commits we do. There are global and repository wide settings/options.
Here is how you can configure settings

If you use --global you will have global settings configured. Those will take affect over each repository. Repository settings have more precedence than global. You need to take --global off from the command to have repository wide options configured. Make sure you are in side repository to configure repository wide options. You don't need to be in repository to set global options.
To view git configured settings, try the command
$ git config --list
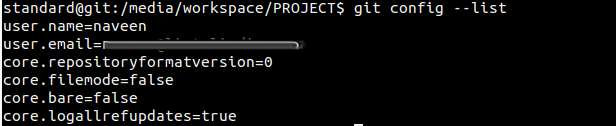
If you use command line option/argument --global that will show all configured global level options.
$ git config –list –global
There are many more options to customize git behavior. But we very few options often.
GIT First Commit:
There are three states in the git commit procedure. Your file resides in any of the following state, those are
- Modified
- Staged
- Commited
Modified means you have changed or added file and have not stored in git database. Staged means you have marked changes in current version to go into next snap shot, that is commit. Committed means, you have saved your modifications into database. The middle state is optional and it is to avoid accidental commits. We can skip this if required but it's not recommended.
Adding files and modifying committed files comes under modified state. If you don't add your new files those will be treated as untracked files.
To add or stage files use the following command.
$ git add file_name
git add is the multi purpose command we use that to both track new files and to stage new files.
Now add first file into our repository

GIT won't track the changes of newly added files unless we say. That is unless we track that file. Newly added files are untracked, git won't show modifications to those files.
Command git status will show us the status inside the repository. It will give the idea about three things, Untracked files, Modified file (Modified files are tracked files ) * Staged files
Here is screen shot where new file will be shown untracked.

Now have this file added into the git database.

The status after we added that file,
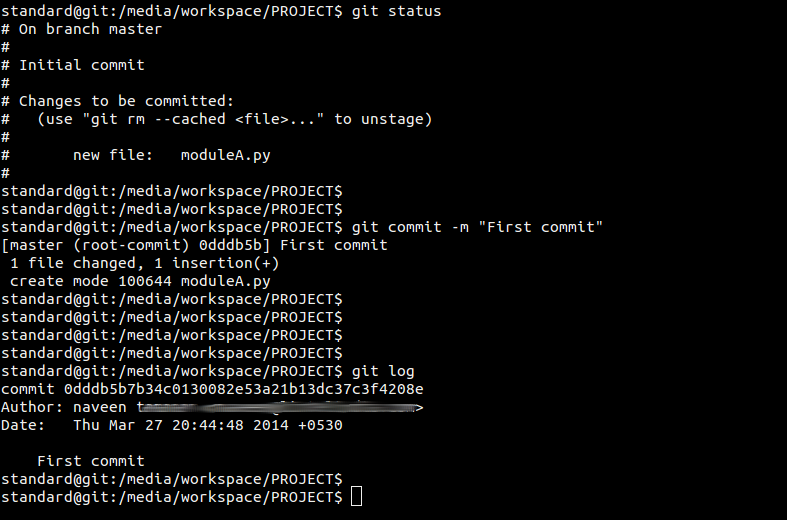
In the above screen shot command git add made the given file stated. The files which are below the secion #changes to be committed are staged files. It's second state as we discussed. Now we have to commit the staged file. The git commit will do that. It will take the argument -m along with the commit message. If we don't give commit message with -m we will have editor open to enter commit message.
Finally, to see our history or previous commits we have the command
git log